
«Data-centric AI» – Eine Veränderung des KI-Mindsets?
Die Digitalisierung ermöglicht die permanente Sammlung und Verarbeitung von verschiedenen Daten rund um das Unternehmen. Die Anzahl dieser Daten ist in den letzten Jahren immer weiter gestiegen. Statista geht von einer Verfünffachung der weltweiten Datenmenge bis 2025 im Vergleich zu 2018 aus [1]. Emergente Technologien und Trends wie Big Data haben zur Entstehung neuer Services und darunterliegender Geschäftsmodelle geführt. In diesem Kontext fokussieren immer mehr Unternehmen die Einführung und das Angebot datengetriebener Services: Daten dringen immer weiter in das Kerngeschäft des Unternehmens vor [2, 3].
Die Daten allein tragen jedoch noch nicht zur Wertschöpfung im Unternehmen bei. Erst wenn Daten mit einer Relevanz und einem Zweck angereichert werden – z. B. durch die Analyse und Verarbeitung – entstehen Informationen und diese können dann im weiteren Verlauf Mehrwert generieren. Um unternehmensrelevante Informationen auszuwerten, setzen Unternehmen vermehrt auf neue Technologien wie künstliche Intelligenz (KI) [4].
Was beinhaltet das Buzzword «künstliche Intelligenz»?
Vorab sei gesagt, dass sich die Wissenschaft bisher nicht auf eine einheitliche Definition der künstlichen Intelligenz einigen konnte. Genau wie bei der menschlichen Intelligenz spielen viele Faktoren eine Rolle: Die menschliche Intelligenz umfasst beispielsweise Gebiete wie die logisch-mathematische Intelligenz aber auch die verbal-linguistische Intelligenz[i]. Bei der künstlichen Intelligenz erstreckt sich das Methodengebiet ähnlich breit von einfachen Berechnungen (Data Analytics) bis hin zur Bild-, Text- und Spracherkennung [5]. Allgemein werden unter dem Buzzword KI intelligente Programme verstanden, die komplexe Aufgaben selbstständig bewältigen können [6].
Um die künstliche Intelligenz weiter zu erklären, erfolgt die Abgrenzung zu oft synonym verwendeten Begriffen wie Machine Learning und Deep Learning. Wie in Abbildung 1 zu erkennen ist, ist Deep Learning ein Teilgebiet des Machine Learnings, was wiederum ein Teilgebiet der künstlichen Intelligenz ist – wer also KI sagt, behält meistens recht. Wer als Experte in diesem Gebiet wahrgenommen werden möchte, kann KI noch weiter spezifizieren, indem er oder sie den Begriff des Machine Learnings oder Deep Learnings verwendet. Man könnte das vermutlich ins Unendliche fortführen, da KI aktuell besonders fleissig erforscht wird – doch dazu später mehr.

Machine-Learning-Methoden haben unterschiedliche Ausprägungen inne und werden für die selbstständige Gewinnung von Erkenntnissen aus Daten verwendet. Es ist somit keine explizite Programmierung für die Lösung eines Problems notwendig [8]. Dabei folgen die Methoden definierten Logiken wie zum Beispiel einer statistischen Regression oder einem Entscheidungsbaum-Algorithmus [9]. Des Weiteren können künstliche neuronale Netze für das Machine Learning verwendet werden. Diese Netze imitieren die Funktionsweise des menschlichen Gehirns und bestehen aus verschiedenen Schichten und Knoten [10]. Informationen und Daten (Input) werden an den Knoten ausgewertet und in die nächste Schicht übertragen. Anschliessend liefert das Netz, genau wie ein Algorithmus, ein Ergebnis (Output).
Beim Machine Learning wird zwischen dem sogenannten Supervised Machine Learning und Unsupervised Machine Learning unterschieden. Beim Supervised Machine Learning muss der Mensch manuell in den Trainingsprozess eingreifen und dem Algorithmus die Ergebnisse der Mustererkennung und ggf. wichtige Merkmale der Daten vorgeben (Abbildung 2: Feature Extraction). Nur so ist der Algorithmus in der Lage, auf Basis dieser Vorgaben einen Zusammenhang zwischen den Inputdaten und dem Output zu erkennen. Das Beispiel von Automobilbildern verdeutlicht den Sachverhalt. Nur wenn der Mensch vorgibt, bei welchen Bildern es sich tatsächlich um Autos handelt, kann der Algorithmus auf unbekannten Bildern Autos als Autos klassifizieren (Abbildung 2: Classification). Das Supervised Learning wird häufig mit dem traditionellen Machine-Learning-Ansatz gleichgestellt. In diesem Kontext wird der Begriff des «Modells» verwendet. Ein Machine-Learning-Modell ist eine Datei, die die beschriebenen Zusammenhänge und Muster beinhaltet und wiederverwendet werden kann [11].
Beim Unsupervised Learning fällt der manuelle Eingriff des Menschen weg und der Algorithmus ist in der Lage, Inputs und Muster selbstständig zu erkennen [6]. Hierbei kommen Cluster-Methoden oder künstliche neuronale Netze zum Einsatz. Vor allem letztere erlauben die selbstständige Analyse, da Daten zwischen den Schichten des Netzes stark verbunden sind und somit Lerneffekte möglich werden. Komplexe (mehrschichtige) künstliche neuronale Netze werden als Deep Learning bezeichnet [6].
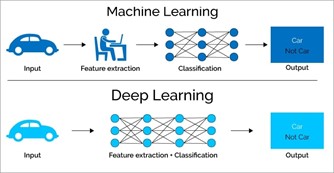
Die Ausführungen zeigen die enge Verzahnung zwischen den unterschiedlichen KI-Begriffen auf. Trainierte Modelle und Erkenntnisse können anschliessend in Programmen verwendet werden, die ein hohes Mass an «Intelligenz» benötigen [6]. Ein Beispiel für ein KI-basiertes Programm ist ein intelligenter Chatbot, der Natural Language Processing (NLP) verwendet und so eine menschen-ähnliche Interaktion ermöglicht [12].
Traditionelle Verwendung von KI und Einschränkungen
Der traditionelle Ansatz von KI stellt den Prozess des Modelltrainings in den Mittelpunkt [13]. Durch die iterative Verbesserung der mathematischen Modelle steigert sich die Qualität der Ergebnisse im Laufe der Zeit («model-centric AI»). Während das Training des Modells grosse Aufmerksamkeit erfährt, stehen die zugrundeliegenden Daten oft im Hintergrund. Vor allem bei Internetkonzernen funktioniert dieser Ansatz besonders gut, da diese über riesige Datenmengen und über die Fähigkeiten zu ihrer Auswertung verfügen. Im Gegensatz dazu gibt es bei diesem Ansatz aufgrund mangelnder Datenmengen kaum Potential für den Einsatz von KI in kleinen Unternehmen [14]. Daher lohnt es sich, einen Blick auf die Daten zu werfen.
Mit Daten verhält es sich wie beim Kochen. Während die Zubereitung der Zutaten eine verhältnismässig lange Zeit in Anspruch nimmt, fällt der eigentliche Prozess des Kochens oft sehr kurz aus. Der Wissenschaftler Andrew Ng nimmt diesen Ansatz auf und überträgt ihn auf KI [15]. Ergebnis dieser Ausführungen ist ein auf den ersten Blick kontraintuitiver Ansatz zum Umgang mit KI. Dieser stellt die Daten in den Mittelpunkt und beschäftigt sich mit der optimalen Vorbereitung und Verwendung der Daten für das Modelltraining («data-centric AI»).
Was genau ist data-centric AI?
Das Konzept «data-centric AI» wird beschrieben als «Übergang vom Modell-Fokus auf den zugrundeliegenden Datensatz, welcher für das Training und die Evaluation des KI-Modells verwendet wird» [16].
Doch was macht Daten aus und welche Eigenschaften müssen bei «data-centric AI» beachtet werden? Datensätze haben verschiedene Eigenschaften, die mithilfe des Konzepts der «seven Vs of Big Data» beschrieben werden können [17] (Abbildung 3). Die Eigenschaft «Volume» beschreibt hierbei den Umfang des Datensatzes, «Velocity» die Geschwindigkeit, mit der dieser generiert und verarbeitet wird. «Variety» umfasst die Vielzahl an verschiedenen Datentypen (Audio, Video, Text), die der Datensatz enthält, während «Veracity» für die Qualität und Konsistenz der Daten steht. Konsistente Daten sind widerspruchsfrei und korrekt. Wenn ein Datenfeld repliziert wird (zum Beispiel in einer anderen Datenbank), müssen alle Replikationen die gleichen Datentypen und Inhalte besitzen [18]. «Validity» untersucht die Sinnhaftigkeit der Daten in Bezug auf das zugrunde liegende Problem. «Volatility» bezeichnet die Veränderungsrate der Daten über ihren Lebenszyklus und kann unter Umständen zum Problem werden – zum Beispiel, wenn es sich bei den Daten um Social-Media-Kommentare handelt, die sich ändern und mit denen andere Nutzer interagieren können. Nur mithilfe einer Datenstrategie und durch die richtige Verwendung von Daten können Unternehmen einen Wert («Value») aus ihnen generieren. «Value» unterstreicht erneut den Ansatz von Andrew Ng.

Während bei Big Data alle 7 Vs betroffen sind, liegt der Schwerpunkt bei «data-centric AI» auf der Menge (Volume) und der Konsistenz und Qualität der Daten (Veracity). Durch die stetige Verbesserung dieser Attribute und damit des Dateninputs soll der Wert der daraus resultierenden Informationen gesteigert werden [19]. Der Fokus verschiebt sich somit von der Quantität der Daten hin zur Qualität. Während «model-centric AI» das Modell optimiert und mit immer neuen Daten füttert, wird bei «data-centric AI» der Modell-Code als unveränderlich angesehen und die gegebene Datenmenge optimiert.
Framework zur Durchführung eines datenzentrierten Machine-Learning-Projektes
Die verbesserten Daten sollen vor allem im Bereich Machine Learning Operations (MLOps) zum Einsatz kommen und dort die Vielzahl an individuellen Methoden zur Bereinigung und Vorbereitung von Daten ersetzen [14]. MLOps beschreibt die Integration und Verwendung von ML-Modellen im Unternehmen in Form von Software. Hierbei stehen die Entwicklung, Bereitstellung und Überwachung der Machine-Learning-Modelle im Vordergrund [20]. Durch systematische Prozesse können ML-basierte Anwendungen effizient und kontinuierlich in Unternehmen integriert werden. Standardisierte Prozesse erlauben zudem die unternehmensübergreifende Integration.
Das vorgestellte datenzentrierte Framework orientiert sich an den Schritten des Lebenszyklus eines ML-Projektes (Abb. 4) und erweitert diesen um folgende Schritte, die in der Abbildung durch die Pfeile dargestellt werden: Nach erfolgreichem Training des Modells wird eine Fehleranalyse durchgeführt, die die Daten identifizieren soll, die dem Modell Probleme bereiten (z. B. Formatierungsfehler beim Zusammenführen von Datensets). Anschliessend können beispielsweise fehlende Einträge korrigiert werden oder die bestehenden Datensätze angepasst werden. Testdatensätze erlauben die Simulation des Modells in einem realen Umfeld. Hierdurch können Rückschlüsse auf die Datenqualität geschlossen und die zugrunde liegende Datenbasis weiter verbessert werden [14].

Vorteile
Der Datenfokus beim Machine Learning lässt sich im Gegensatz zum traditionellen Ansatz in allen Industrien umsetzen und ist nicht von grossen Datenmengen abhängig. Eine Studie von «LandingAi» zeigt direkt messbare Verbesserungen in KI-Projekten durch die Einführung des neuen Ansatzes. Vor allem das Training des Modells (10-mal schneller) sowie die Zeit von Entwicklungsbeginn bis zum produktiven Einsatz eines Modells haben sich durch die Verwendung des datenzentrierten Ansatzes enorm verkürzt (bis zu 65 %). Zudem wird von bis zu 40 % genaueren Modellen berichtet. Die gemeinsame Erarbeitung von Standards (ML-Ops Framework) steigert die Kollaboration zwischen Qualitätsmanagern, Experten und Entwicklern und ermöglicht somit die effizientere Durchführung von KI-Projekten [19]. Neben verbesserter Datenqualität und verringerter Redundanz profitieren Unternehmen von «data-centric AI» durch niedrigere Kosten und klare Datenstrukturen. Dadurch, dass die Qualität der Inputdaten für KI-Programme verbessert wird, erhöht sich das Vertrauen in die daraus gewonnen Informationen und die auf Basis dieser Informationen getroffenen Entscheidungen [22].
Herausforderungen
Die verwendeten Daten müssen stets aktuell gepflegt sein, um von den Mehrwerten dieses Konzepts zu profitieren. Daher sind das Monitoring der Daten sowie deren Anpassung relevante Herausforderungen in diesem Themengebiet [23, 24]. Datenanpassungen betreffen zum Beispiel die Struktur der Daten (Listen, Felder), Datentypen (Buchstaben, Zahlen) oder Messeinheiten (Liter, Euro). Mithilfe des Monitorings können die Daten beobachtet werden und Veränderungen von Datensätzen gut nachvollzogen werden. Dieser Schritt ist besonders relevant, da die Performance des KI-Modells nun hauptsächlich von der Datenbasis abhängig ist. Domain-Experten spielen eine wichtige Rolle bei «data-centric AI». Durch zusätzliches Kontextwissen in ihren jeweiligen Fachbereichen können sie die Anforderungen an die Daten präziser formulieren und ihre Einhaltung überprüfen und somit die Qualität der Ergebnisse stark beeinflussen [22].
Mögliche Anwendungsgebiete in der Finanzindustrie
Big Data wird derzeit in unterschiedlichen Bereichen der Finanzindustrie für den Einsatz von KI-Technologien verwendet. Hierzu zählen zum Beispiel Algo-Trading, Asset Management und Kreditwürdigkeitsprüfungen [25]. Die Einführung einheitlicher Datenstandards sowie die Verbesserung der Datenqualität sorgen auch in diesen Bereichen für verbesserte Ergebnisse der KI-Technologien. Des Weiteren eröffnet «data-centric AI» neue Möglichkeiten für den Einsatz von KI in der Finanzindustrie. So können auch kleinere Datenbestände bereits für die Analyse durch KI-Technologien verwendet werden. Konkrete Anwendungsfälle gibt es in der Finanzindustrie bisher nicht, da data-centric AI ein sehr aktuelles Phänomen ist und Banken aufgrund ihrer geringen Risikobereitschaft gewiss nicht zu den «Early Adopters» gehören.
Dennoch ist es für Banken von enormer Bedeutung diesen Trend zu kennen und sich im Allgemeinen bei kleinen Datenmengen deutlich stärker auf die Datenqualität zu fokussieren. Immer wieder treten in der Finanzindustrie sowie in anderen Branchen volkswirtschaftliche Schocks auf, die dank der Globalisierung kurzfristig sämtliche Unternehmen weltweit betreffen. Unternehmen können dabei nicht mehr auf ihre Unmengen an historischen Daten zurückgreifen, die in einem anderen Kontext entstanden sind und daher nicht dazu geeignet sind, die Zukunft zu prognostizieren. Ein solcher Schock trat auch zu Beginn der Corona-Pandemie auf: Zu Beginn der Pandemie änderten sich plötzlich Zahlungsmuster der Kundinnen und Kunden, was die Betrugserkennung erheblich erschwert haben dürfte. Des Weiteren wurden plötzlich kurzfristige Kredite von vornehmlich kleineren Unternehmen angefragt, um den kommenden Lockdown überstehen zu können – mit welchem Ausfallrisiko bewertet man diese Fälle? Wie errechnet sich der zu zahlende Zinssatz in einer Ausnahmesituation? Bei genau solchen Fällen kann data-centric AI unterstützen: Statt den Fokus auf Big Data zu setzen, liegt dieser nun auf der Qualität der Daten. Diese soll über den gesamten ML-Lebenszyklus gewährleistet werden und mithilfe von systematischen und effizienten Prozessen in MLOps-Aktivitäten eingebettet werden. Somit erhalten Unternehmen, die aus diversen Gründen nicht über Big Data verfügen, dennoch eine Möglichkeit, KI-Technologien Erfolg bringend einzusetzen. Aber auch erfahrene Unternehmen profitieren im Umgang mit KI von einer Steigerung der Datenqualität durch die messbare Verbesserung ihrer KI-gestützten Analysen.
Weiterführende Links
[i] Mit verschiedenen Arten von Intelligenz und der Frage, ab wann eine Maschine als intelligent eingestuft werden kann, beschäftigt sich Christian Dietzmann im Beitrag Ist das schon Künstliche Intelligenz?
[1] Tenzer, F., “Daten – Volumen der weltweit generierten Daten 2025”, Statista, 2020. https://de.statista.com/statistik/daten/studie/267974/umfrage/prognose-zum-weltweit-generierten-datenvolumen/ [2] Dr. Hoßbach, N., “Datengetriebene Geschäftsmodelle”, Arbeitsgruppe für Supply Chain Services des Fraunhofer IIS. https://www.scs.fraunhofer.de/de/forschungsfelder/datengetriebene-geschaeftsmodelle.html [3] Dr. Rieger, V., and D. Dr. Drube, “Service- und datenzentrierte Geschäftsmodelle auf Basis von IoT und Industrie 4.0”, 2019. https://detecon.com/de/journal/service-und-datenzentrierte-geschaeftsmodelle-auf-basis-von-iot-und-industrie-40 [4] Kiron, D., and M. Schrage, “Strategy For and With AI”, MIT Sloan Management Review, 2019. [5] Dietzmann, C., and R. Alt, “Assessing the Business Impact of Artificial Intelligence”, (2020). [6] Tiedemann, M., “KI, künstliche neuronale Netze, Machine Learning, Deep Learning: Wir bringen Licht in die Begriffe rund um das Thema „Künstliche Intelligenz“”, Alexander Thamm GmbH, 2018. https://www.alexanderthamm.com/de/blog/ki_artificial-intelligence-ai-kuenstliche-neuronale-netze-machine-learning-deep-learning/ [7] Holzinger, A., P. Kieseberg, E. Weippl, and A.M. Tjoa, “Current Advances, Trends and Challenges of Machine Learning and Knowledge Extraction: From Machine Learning to Explainable AI”, Machine Learning and Knowledge Extraction, Springer International Publishing (2018), 1–8. [8] Wolfewicz, A., “Deep learning vs. machine learning – What’s the difference?”, Levity, 2021. https://levity.ai/blog/difference-machine-learning-deep-learning [9] Wuttke, L., “Machine Learning vs. Deep Learning: Wo ist der Unterschied?”, datasolut GmbH, 2021. https://datasolut.com/machine-learning-vs-deep-learning/ [10] Garbade, D.M.J., “Clearing the Confusion: AI vs Machine Learning vs Deep Learning Differences”, Medium, 2021. https://towardsdatascience.com/clearing-the-confusion-ai-vs-machine-learning-vs-deep-learning-differences-fce69b21d5eb [11] QuinnRadich, “Was ist ein Machine Learning-Modell?”, https://docs.microsoft.com/de-de/windows/ai/windows-ml/what-is-a-machine-learning-model [12] Weber, R., “Chatbot Arten: Klick-Chatbot vs. NLP-Chatbot”, moin.ai, 2021. https://www.moin.ai/blog/natuerliches-sprachverstandnis-nlp-vs-gefuehrte-chat-dialoge [13] Radečić, D., “Data-centric vs. Model-centric AI? The Answer is Clear”, Medium, 2021. https://towardsdatascience.com/data-centric-vs-model-centric-ai-the-answer-is-clear-4b607c58af67 [14] Press, G., “Andrew Ng Launches A Campaign For Data-Centric AI”, Forbes. https://www.forbes.com/sites/gilpress/2021/06/16/andrew-ng-launches-a-campaign-for-data-centric-ai/ [15] DeepLearningAI, A Chat with Andrew on MLOps: From Model-centric to Data-centric AI, 2021. [16] “NeurIPS Data-Centric AI Workshop”, 2021. https://datacentricai.org/ [17] Khan, M.A., M.F. Uddin, and N. Gupta, “Seven V’s of Big Data understanding Big Data to extract value”, Proceedings of the 2014 Zone 1 Conference of the American Society for Engineering Education, (2014), 1–5. [18] “Datenkonsistenz”, https://www.gif-ev.de/glossar/view_contact/458 [19] Landing AI, “Data-Centric AI”, Landing AI, 2022. https://landing.ai/data-centric-ai/ [20] Wuttke, L., “Was ist ML-Ops? (Machine Learning Operations)”, datasolut GmbH. https://datasolut.com/wiki/was-ist-mlops/ [21] Muaz, U., “From Model-centric to Data-centric Artificial Intelligence”, Medium, 2021. https://towardsdatascience.com/from-model-centric-to-data-centric-artificial-intelligence-77e423f3f593 [22] Patel, H., “Data-Centric Approach vs Model-Centric Approach in Machine Learning”, neptune.ai, 2021. https://neptune.ai/blog/data-centric-vs-model-centric-machine-learning [23] Clemente, F., “From model-centric to data-centric”, Medium, 2021. https://towardsdatascience.com/from-model-centric-to-data-centric-4beb8ef50475 [24] Polyzotis, N., and M. Zaharia, “What can Data-Centric AI Learn from Data and ML Engineering?”, arXiv:2112.06439 [cs], 2021. [25] OECD, ed., Sustainable and resilient finance, OECD, Paris, 2020.
{kind=link}

Leipzig in Wirtschaftsinformatik mit dem Forschungsschwerpunkt disruptive Technologien. Seitdem untersucht er den Einfluss
von künstlicher Intelligenz und Blockchain auf Unternehmen in verschiedenen Industrien. Derzeit studiert Lasse im Master Wirtschafsinformatik.
