
Data Lineage: Ein Weg zum datengetriebenen Unternehmen?
In den letzten Jahren ist der Ruf nach datengetriebenen Entscheidungen und Prozessen in Unternehmen jeglicher Branche stark gewachsen. Datengetriebene Unternehmen[a] wie Apple, Alphabet oder Microsoft zählen mittlerweile zu den wertvollsten Unternehmen der Welt [2]. Doch um datengetriebene Entscheidungen treffen zu können, müssen unterschiedliche Herausforderungen rund um ein Unternehmen und dessen Daten(management) gelöst werden. Hierzu zählen die Etablierung einer datengetriebenen Kultur [3] sowie die Einführung und Umsetzung einer Datenstrategie [4]. Eine weitere grosse Herausforderung stellt für viele Unternehmen der Überblick über die eigenen Datenbestände dar. In diesem Kontext sind Unternehmen mit den folgenden Fragen konfrontiert: Welche Rolle spielen meine Daten bei der Wertschöpfung und wie werden sie in Prozessen verwendet? Aus welchen Beständen stammen meine Daten und für welche Produkte, Services und Anwendungen werden sie genutzt [5]? Auch in der Finanzindustrie spielt der Überblick über die eigenen Daten eine immer wichtigere Rolle. Banken müssen ihre Daten dem Regulator jederzeit offenlegen können, regelmässiges Reporting wird zum Normalzustand [6]. Das Thema der Transparenz wird immer wichtiger, es bedarf daher einer Lösung, um den Überblick über die eigenen Daten behalten zu können.
In diesem Kontext hat sich das Prinzip der «Data Lineage» (DL) etabliert. Aufbauend auf dem Ansatz des Metadatenmanagements ermöglicht dieses Konzept die Strukturierung und Visualisierung der eigenen Datenbestände und -quellen [7]. Der folgende Beitrag erläutert die wichtigsten Grundlagen des Themengebiets «Data Lineage» und zeigt mögliche Anwendungsgebiete in der Finanzindustrie auf.
Grundlagen zu Metadaten
Metadaten werden häufig als «Daten über Daten» bezeichnet [8] und beschreiben strukturiert unterschiedliche Arten von Ressourcen im Unternehmen (z. B. Daten, Dokumente, Personen, Orte, Gebäude, Konzepte) [9]. Durch die Verwendung von Metadaten wird garantiert, dass jede Ressource auf Datenebene eine einheitliche Struktur besitzt und von jedem Anwender gleich interpretiert werden kann. Ein Beispiel untermalt die Ausführungen: um in einem Unternehmen alle Mitarbeiter eindeutig identifizieren zu können, werden standardisierte Metadaten für die Beschreibung von Mitarbeitern verwendet. Im Falle des Mitarbeiters sind dies eine eindeutige ID, der Name der Person, der Geburtstag, die Wohnadresse oder der Familienstand. Die Verwendung der Metadaten ermöglicht die eindeutige Identifikation, auch im Falle von übereinstimmenden Namen (Mitarbeit X und Y heissen Schmidt, haben aber eine eindeutige ID).
Es existieren grundsätzlich 5 unterschiedliche Arten von Metadaten (siehe Tabelle 1) [9]. Beschreibende Metadaten (1) werden für die eindeutige Identifikation von Ressourcen im gesamten Unternehmen verwendet (siehe Beispiel: Mitarbeiter). Neben dem Titel der Ressource können Informationen zum Entstehungsdatum oder dem Urheber abgerufen werden. Administrative Metadaten (2) ermöglichen die Verwaltung von Ressourcen. Dies beinhaltet Informationen zur Herkunft und Archivierung der Ressourcen. Content-Ratings-Metadaten (3) zeigen mögliche Nutzer(gruppen) der Ressource innerhalb des Unternehmens auf. Im Gegensatz dazu erlauben Relationship-Metadaten (4) Beziehungen zwischen unterschiedlichen Ressourcen zu beschreiben. Somit kann beispielsweise festgestellt werden, welche Produkte von welchen Kunden gekauft werden. Meta-Metadaten (5) sind für die Verwaltung der bestehenden Metadaten verantwortlich. Mithilfe von Meta-Metadaten werden Formate für die Speicherung oder die verwendete Syntax, d. h. die Struktur der Daten, festgelegt, sodass Daten von der im Unternehmen genutzten Software interpretiert, korrekt dargestellt und verarbeitet werden können.

Das Metadatenmanagement ist für die Verwaltung der Metadaten eines Unternehmens zuständig [10]. Es stellt eine wichtige Unternehmensfunktion dar und existiert bereits seit den 1990er Jahren. Während das Metadatenmanagement zunächst in IT-Abteilungen entstand (in denen grosse Mengen unterschiedlichster Daten vorlagen), entwickelte sich das Konzept über die Jahre weiter und wurde zum wichtigen Bestandteil der Data Governance[b] und des gesamten Unternehmens [12]. Es bildet die Grundlage für die Analyse und Verwendung von Unternehmensdaten. Es zeigt sich: neben den tatsächlichen Ausprägungen der Daten (Mitarbeiter X, Y) müssen Unternehmen die Meta- und Kontextdaten (Attribute: ID, Name, Geburtstag etc.) pflegen, anderenfalls fehlen wichtige Informationen für die Datenverarbeitung.
Data Lineage

Das Konzept der Data Lineage baut auf den Ansätzen des Metadatenmanagements auf und zielt auf die Analyse und Visualisierung von Datenflüssen im Unternehmen ab. Data Lineage orientiert sich am gesamten Datenlebenszyklus (siehe Abbildung 1), von der Entstehung bis zum Löschen der Daten [14]. Ein besonderer Fokus liegt dennoch auf dem Ursprung der Daten sowie der Nachvollziehbarkeit der Daten bis zum Ort der Nutzung [15].
Ausprägungen und Implementierung der Data Lineage
Es wird zwischen zwei grundlegenden Arten der Data Lineage unterschieden [14] (siehe Abbildung 2).

Die Business Lineage (1) ermöglicht die oberflächliche Nachverfolgung von Datenströmen, Datenquellen und Verwendungsorten in Abhängigkeit zu den Geschäftsprozessen und erlaubt Anwendern die Visualisierung auf inhaltlicher Ebene [16]. Somit können Business-Probleme besser nachvollzogen werden und durch zusätzliches Kontextwissen und Datenquellen angereichert werden. Vor allem für die Nachvollziehbarkeit von Berichten eignet sich die Business Lineage (siehe Abbildung 3). Echte Geschäftsprozesse (Marketing, Sales) dienen als Datengrundlage, die verwendeten Daten werden auf unterschiedliche Arten verarbeitet und anschliessend in Berichten dargestellt. Die Darstellung dieser Datenflüsse steigert die Transparenz und das Vertrauen in die erstellten Berichte [14].
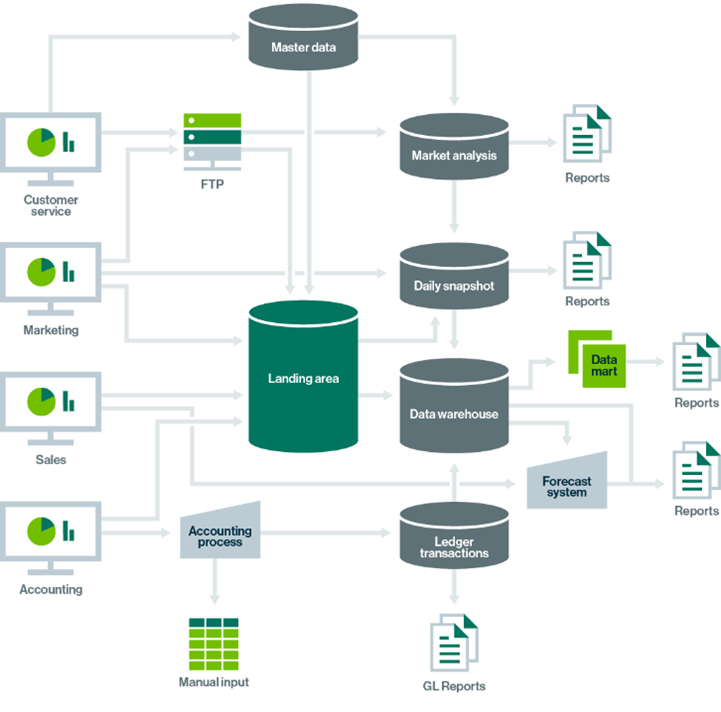
Bei der technischen Lineage (2) erhalten Entwickler und IT-Administratoren vollen Zugriff auf die Datenströme und -quellen und sind anschliessend in der Lage, diese auf Ebene von Tabellen, Zeilen und Warteschlangen zu verarbeiten und zu analysieren. Abhängigkeiten zwischen Daten können frühzeitig erkannt werden und für die Konfiguration der gesamten IT- und Datenlandschaft berücksichtigt werden.
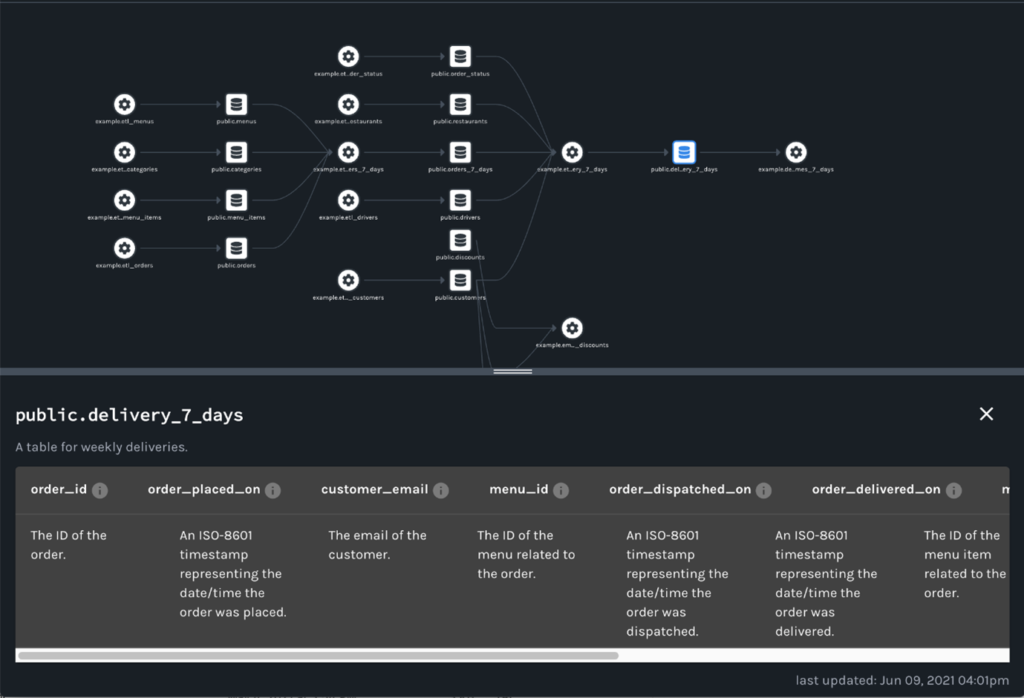
Um das Konzept der Data Lineage umsetzen zu können, müssen drei grundlegende Prozesse durchgeführt werden. Im ersten Schritt müssen alle relevanten Metadaten gesammelt werden (1). Zudem werden in diesem Schritt die Abhängigkeiten zwischen den einzelnen Metadaten hergestellt. Anschliessend müssen in Schritt zwei die neuen Metadaten mit den bestehenden Metadaten konsolidiert und verglichen werden (2). Im letzten Schritt müssen die Metadaten repräsentiert werden (3), sodass diese durch die Anwender interpretiert werden können. Dies beinhaltet die Visualisierung der Datenabhängigkeiten. In diesem Zuge kommt das Konzept eines Knowledge Graph zum Einsatz [16]. Mithilfe eines Knowledge Graph können die Metadaten in einem Netzwerk dargestellt werden. Dieses Netzwerk zeigt die Relationen zwischen den Metadaten auf und ermöglicht somit den Anwendern die Zusammenhänge in den Datenstrukturen zu erkennen [17]. Hierfür existieren zwei unterschiedliche Standards, die im Kontext der Data Lineage häufig verwendet werden: der OpenLineage-Standard sowie der PROV-O-Standard [16]. Ein Beispiel der OpenLineage-Repräsentation befindet sich am Ende dieses Beitrages.

Vorteile und Herausforderungen
Die durchgehende Dokumentation, Analyse und Visualisierung der Datenströme ermöglicht Unternehmen die Potenziale der eigenen Daten besser auszuschöpfen. Durch ein ausgeprägtes Datenverständnis steigt das Vertrauen in die verwendeten Daten. Datenquellen und -ströme sind für Anwender und Administratoren transparent gestaltet und können zu jedem Zeitpunkt nachvollzogen werden [14]. Somit können Unternehmen zeit- und kosteneffizient Anpassungen an den Datenströmen und der IT-Landschaft vornehmen. Beispielsweise erlaubt die Technical Lineage es (nach Aussage von Collibra) der IT-Abteilung, die Analysen der Datenströme bis zu 98 % effizienter vorzunehmen [5]. Auch Fehlerursachen können schnell gefunden und behoben werden [16]. Des Weiteren erhalten Business-Anwender zusätzliche Informationen, welche im Alltag bei der Arbeit (siehe Beispiel: Berichterstellung) oder bei der Entscheidungsfindung unterstützen können. Dies steigert die datengetriebene Wertschöpfung innerhalb des Unternehmens. Ein weiterer Vorteil der Data Lineage liegt im effizienten Reporting gegenüber dem Regulator. Dieses wird beispielsweise durch die BCBS 239 [18] (ein Standardregelung für Risikoberichterstattungen von Kreditinstituten) oder die GDPR (Datenschutzgrundverordnung) [13] gefordert. Unternehmen können diese Berichte durch den permanenten Überblick über die kritische Dateninfrastruktur schneller erstellen. Wie bereits zu Beginn dieses Beitrages erläutert, stellt ein strukturiertes und gut definiertes Metadatenmanagement die Grundlage für erfolgreiche Data-Lineage-Projekte dar. Aus diesem Grund kann ein effektives Metadatenmanagement als Voraussetzung für die erfolgreiche Implementierung der Data Lineage betrachtet werden. Neben Zugangsrechten muss die Dynamik der Metadaten berücksichtigt werden und durch geeignete Systeme erfasst werden. Datenquellen und -ströme können sich mit der Zeit verändern und müssen konstant durch das Metdatenmanagement angepasst werden [19]. Zudem sollten die theoretischen Zusammenhänge der Metadaten stets mithilfe von Ontologien dokumentiert werden [20]. Vor allem Beziehungen und Abhängigkeiten sind sehr gut durch Ontologien erkennbar.
Use Case aus der Finanzindustrie
Vor allem in der Finanzindustrie sind die angesprochenen Vorteile der Data Lineage von grosser Bedeutung. Neben Gesetzen wie der GDPR müssen Banken immer neue regulatorische Anforderungen erfüllen [22]. So fordert zum Beispiel das Targeted Review of Internal Models (TRIM) der europäischen Zentralbank, dass Banken ihre internen Modelle zur Berechnung von Asset-Werten und den damit verbundenen Risiken offenlegen [23]. In diesem Kontext ermöglicht das Konzept der Data Lineage die Offenlegung von Datenströmen und internen Modellen gegenüber Dritten. Neben der Datenverarbeitung spielt auch der Datenschutz eine wichtige Rolle in einer Bank. Mithilfe der Data Lineage können Banken Einblick in Prozesse und Systeme erhalten, in denen personenbezogene Daten verarbeitet werden und daher besonders schützenswert sind [22].
Fazit
Data Lineage stellt einen wichtigen Bestandteil für Unternehmen auf dem Weg zum datengetriebenen Unternehmen dar. Dank verschiedener Ansätze lässt sich die Darstellung der Unternehmensdaten sowie deren Datenflüsse auf unterschiedliche Anwendergruppen (Technical und Business Lineage) anpassen. Die wichtigste Grundlage spielen in diesem Kontext die Metadaten des Unternehmens sowie deren Management. Neben den Metadaten müssen dennoch weitere Unternehmensbereiche wie die datengetriebene Kultur und die Datengovernance weiter fokussiert und gefördert werden [16]. Gartner spricht daher von Active Metadata, dem Prinzip der permanenten Analyse der Metadaten in Abhängigkeit von Nutzern, dem Datenmanagement, Systemen und Infrastrukturen sowie der Datengovernance [24].
[a] Datengetrieben bedeutet hier, dass Daten die Grundlage für Entscheidungen im Unternehmen bilden [1]
[b] Zuweisung von Entscheidungsrechten und damit verbundenen Pflichten bei der Verwaltung von Daten in Unternehmen [11]
Quellen
[1] Bleiholderoc, J., “Auf dem Weg zum datengetriebenen Unternehmen: Was es bedeutet datengetrieben zu sein und welche Themenfelder wichtig sind (Teil 1/3)”, The Cattle Crew Blog, 2020. https://thecattlecrew.net/2020/03/25/auf-dem-weg-zum-datengetriebenen-unternehmen-teil-1/ [2] Gourévitch, A., L. Faeste, E. Baltassis, and J. Marx, “Data-driven Transformation”, bcg.perspectives, 2017. [3] Waller, D., “10 Steps to Creating a Data-Driven Culture”, Harvard Business Review, 2020. https://hbr.org/2020/02/10-steps-to-creating-a-data-driven-culture [4] DalleMule, L., and T.H. Davenport, “What’s Your Data Strategy?”, Harvard Business Review, 2017. https://hbr.org/2017/05/whats-your-data-strategy [5] Collibra, “The top benefits of data lineage”, Collibra, 2020. https://www.collibra.com/us/en/blog/the-top-benefits-of-data-lineage [6] “Regulatorisches Meldewesen für Banken”, https://www.ppi.de/banken/regulatorische-anforderungen/regulatorisches-meldewesen/ [7] “Data lineage: Data origination and where it moves over time”, Deloitte Netherlands. https://www2.deloitte.com/nl/nl/pages/financial-services/articles/data-lineage.html [8] Sebastian-Coleman, L., Measuring Data Quality for Ongoing Improvement: A Data Quality Assessment Framework, Newnes, 2012. [9] Rühle, S., “Kleines Handbuch Metadaten”, pp. 10. [10] Hüner, K.M., B. Otto, H. Österle, and B. Brauer, “Fachliches Metadatenmanagement mit einem semantischen Wiki”, HMD Praxis der Wirtschaftsinformatik 48(1), 2011, pp. 98–108. [11] Otto, B., “Data Governance”, Business & Information Systems Engineering 3(4), 2011, pp. 241–244. [12] Prukalpa, “The Gartner Magic Quadrant for Metadata Management was just scrapped.”, Medium, 2021. https://towardsdatascience.com/the-gartner-magic-quadrant-for-metadata-management-was-just-scrapped-d84b2543f989 [13] “The 5 stages of Data LifeCycle Management – Data Integrity”, Dataworks, 2019. https://www.dataworks.ie/5-stages-in-the-data-management-lifecycle-process/ [14] Collibra, “What is data lineage and why is it important?”, Collibra, 2022. https://www.collibra.com/us/en/blog/what-is-data-lineage [15] International, D., DAMA-DMBOK: Data Management Body of Knowledge: 2nd Edition, Technics Publications, Basking Ridge, New Jersey, 2017. [16] Loyens, J., “How Should We Be Thinking about Data Lineage?”, Medium, 2022. https://towardsdatascience.com/how-should-we-be-thinking-about-data-lineage-541ca5ab83d0 [17] IBM Cloud Education, “What is a Knowledge Graph?”, 2021. https://www.ibm.com/cloud/learn/knowledge-graph [18] “Principles for effective risk data aggregation and risk reporting”, 2013. [19] “Challenges to Managing Metadata”, Data and Technology Today, 2013. https://datatechnologytoday.wordpress.com/2013/01/12/challenges-to-managing-metadata/ [20] Missier, P., P. Alper, O. Corcho, I. Dunlop, and C. Goble, “Requirements and Services for Metadata Management”, Internet Computing, IEEE 11, 2007, pp. 17–25. [21] Pathak, J., D. Caragea, and V. Honavar, “Ontology-Extended Component-Based Workflows”, 2004. [22] Hermeling, M., “‘Back to the Roots’ – Why Data Lineage is Key for Financial Services Firms”, International Banker, 2019. https://internationalbanker.com/technology/back-to-the-roots-why-data-lineage-is-key-for-financial-services-firms/ [23] “Targeted Review of Internal Models – TRIM”, Deloitte Deutschland. https://www2.deloitte.com/de/de/pages/financial-services/articles/targeted-review-of-internal-models-trim.html [24] “Active Metadata Management: Why Is It Essential in 2022?”, Atlan. https://atlan.com/active-metadata-management/ [25] “Quickstart”, Marquez. https://marquezproject.github.io/marquez/quickstart.html

Leipzig in Wirtschaftsinformatik mit dem Forschungsschwerpunkt disruptive Technologien. Seitdem untersucht er den Einfluss
von künstlicher Intelligenz und Blockchain auf Unternehmen in verschiedenen Industrien. Derzeit studiert Lasse im Master Wirtschafsinformatik.