
Synthetische Daten – Die Zukunft datengetriebener Finanzservices?
Die Zukunft der Banken ist von der erfolgreichen digitalen Transformation abhängig. Eine der grössten Herausforderungen in diesem Kontext ist der Umgang mit bankspezifischen und personenbezogenen Daten sowie deren Verarbeitung durch künstliche Intelligenz (KI). KI stellt eine disruptive Technologie in der Finanzindustrie dar und kann entlang des gesamten Wertschöpfungsprozesses eingesetzt werden [1]. Beispielhafte Anwendungen von KI in der Finanzindustrie sind automatisierte Know-Your-Customer-Prozesse [2] und Anti-Money-Laundering-Aktivitäten [3]. Die Verwendung von KI ermöglicht ausserdem das Angebot von datengetriebenen Services gegenüber dem Kunden. Grundlage datenbasierter Services ist eine hochwertige und aktuelle Datenbasis. Dies beinhaltet Inputfaktoren wie die Qualität und Quantität der Daten. Das Beispiel Anti-Money Laundering verdeutlicht dies: nur eine qualitativ hochwertige und in der Datenmenge angemessene Datenbasis ermöglicht die datengetriebene Mustererkennung von illegalen Geldwäscheaktivitäten. Vor allem die Menge der richtig erkannten Betrugsfälle (true positive) ist oft sehr gering.
Doch nicht alle Unternehmen verfügen über eine ausreichend grosse Datenbasis zum Trainieren eines Algorithmus und das Teilen und die grundsätzliche Nutzung mancher Daten ist – teilweise auch innerhalb des Unternehmens – streng limitiert. Besonders die in Europa geltende Datenschutzgrundverordnung (DSGVO) erschwert die Handhabung persönlichkeitsbezogener Daten. Somit ist es der Bank nur begrenzt möglich, eine solide Datenbasis für die Verwendung und das Trainieren einer KI zu sammeln. In Folge sinken die Effizienz, das Vertrauen in sowie die Entscheidungsfähigkeit dieser Technologie [4]. Für Anti-Money-Laundering-Aktivitäten bedeutet dies, das illegale Aktivitäten schwer zu erkennen sind: Je nach Sensitivität des Algorithmus werden Betrugsfälle zu selten erkannt (false negative) oder es werden Transaktionen als Betrugsfälle klassifiziert, die eigentlich keine sind (false positive). Werden zu wenige Betrugsfälle erkannt, scheinen die finanziellen Ressourcen verschwendet, die zur Entwicklung des Algorithmus aufgewendet wurden; werden zu viele Betrugsfälle erkannt, so muss die Bank zu vielen Verdachtsfällen nachgehen, was ebenfalls Ressourcen beansprucht.
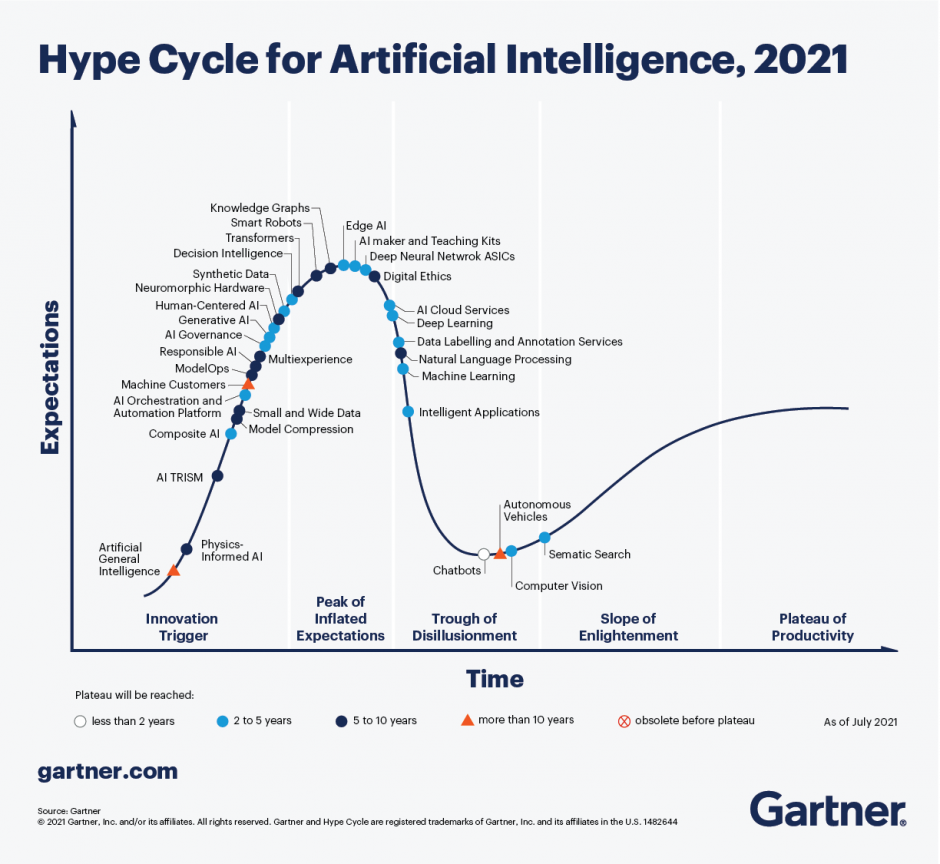
Um diesen Problemen entgegenzuwirken hat sich das Konzept synthetischer Daten etabliert. Der Gartner Hype Cycle 2021 stuft synthetische Daten als sehr relevant («emerging technologies») für die KI-Forschung ein und erwartet, dass die Technologie innerhalb der nächsten fünf Jahre so weit ausgereift ist, dass sie von einer breiten Masse an Unternehmen eingesetzt wird [5]. Mithilfe dieser Daten können Banken weiterhin hochwertige und effiziente KI-Modelle unter Beachtung der Datenschutzverordnung anlernen. Im Fall von Anti-Money-Laundering-Aktivitäten ermöglichen synthetische Daten das Teilen von anonymen Daten, sodass Banken ihre Algorithmen mit mehr Daten versorgen können, was zur Identifikation von Betrugsszenarien dient [6]. Dieser Blogbeitrag führt Leserinnen und Leser an das Themengebiet der synthetischen Daten im Kontext der Finanzindustrie heran.
Definition und Referenzprozess zur Erstellung von synthetischen Daten
Synthetische Daten werden künstlich erzeugt und stellen eine Abstraktion realer Daten dar. Hierbei werden Eigenschaften bestehender Daten analysiert und für den Aufbau eines künstlichen Datensatzes verwendet [7]. Diese Abstraktion ermöglicht eine anonymisierte Verwendung der Originaldaten [8]. Der künstliche Datensatz besitzt die identischen statistischen Informationen sowie Datenstrukturen [9]. Im Beispiel Anti-Money Laundering können auf Basis von realen Kundendaten und Banktransaktionen synthetische Daten für die Mustererkennung von Geldwäsche-Aktivitäten erzeugt werden. Dieser Prozess verwendet reale Daten wie Account-Eröffnungen, Zahlungen und Käufe [10]. Die neu erzeugten künstlichen Daten beinhalten keine persönlichkeitsbezogenen Daten, stellen dennoch die statistische Abstraktion der realen Kunden- und Transaktionsdaten dar. Somit werden benötigte Muster unter Wahrung des Datenschutzes weiterhin durch den synthetischen Datensatz repräsentiert.
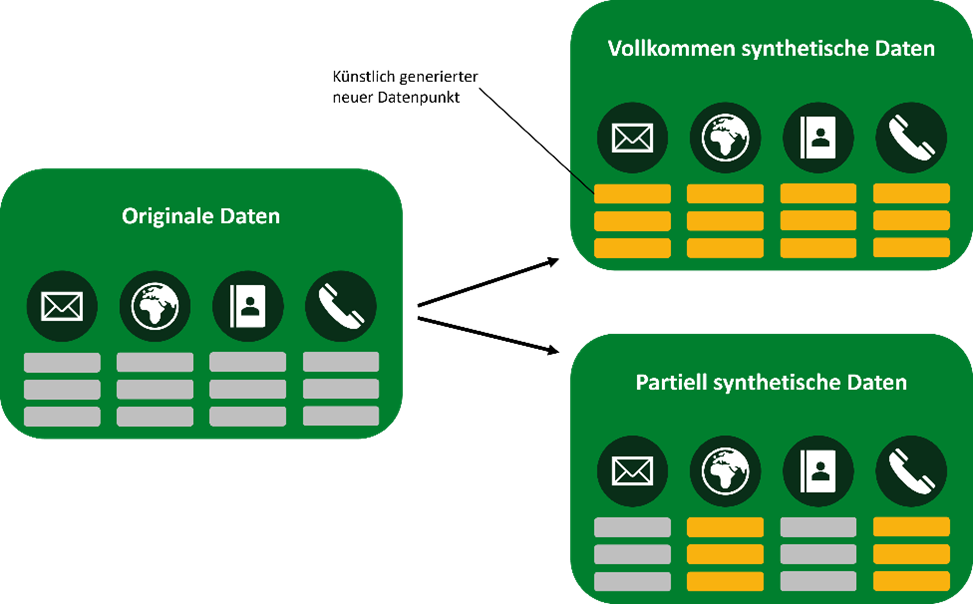
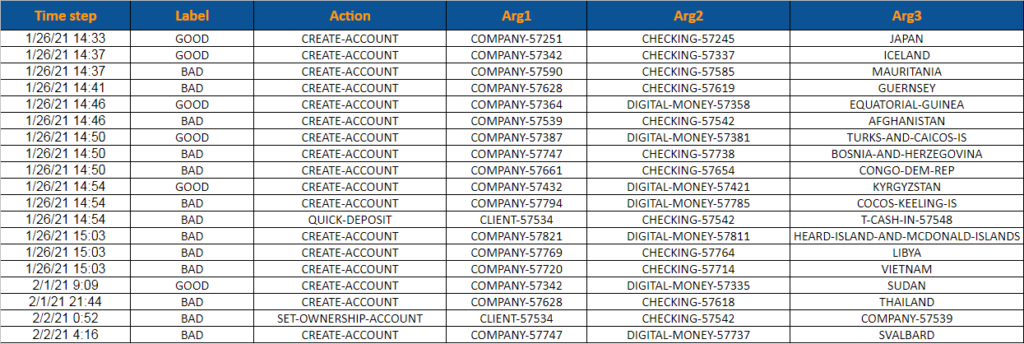
Synthetische Daten ermöglichen die Erweiterung bestehender Datensätze (partiell synthetische Daten) oder die Erstellung neuer künstlicher Datensätze (vollkommen synthetische Daten). Bei der Erweiterung eines bestehenden Datensatzes werden nur einzelne Spalten einer Datenbanktabelle gegen künstlich erzeugte Daten ausgetauscht. Ein Beispiel: der Originaldatensatz beinhaltet 3 Spalten, diese beinhalten Informationen über «Ort», «Zeit» und «Transaktionspartner». Der partiell synthetische Datensatz verwendet weiterhin die Spalte «Zeit» aus dem originalen Datensatz, abstrahiert aber die Eigenschaften der Spalten «Transaktionspartner» und «Ort». Vollkommen synthetische Datensätze besitzen keine inhaltlichen Informationen des originalen Datensatzes [9]. Somit würde auch die Spalte «Zeit» im vollkommen synthetischen Datensatz abstrahiert werden, würde aber die gleichen Muster der Daten innerhalb des Datensatzes aufweisen. Abbildung 3 zeigt einen exemplarisch generierten synthetischen Datensatz für das Anti-Money Laundering.
Zusammengefasst sind die Vorteile von synthetischen Daten also die skalierbare Generierung von zusätzlichen Daten, die als Input für KI-basierte Modelle dringend gebraucht werden. Ihre Anwendung löst zusätzlich das Problem des Datenschutzes, da keine persönlichen Daten im (vollkommen) synthetischen Datensatz enthalten sind und Daten in partiell synthetischen Datensätzen nicht realen Personen zugeordnet werden können.
Für die Erstellung synthetischer Daten existieren unterschiedliche Ansätze. Zur Generalisierung des Sachverhaltes stellt dieser Beitrag einen Referenzprozess von J.P. Morgan AI Research vor.
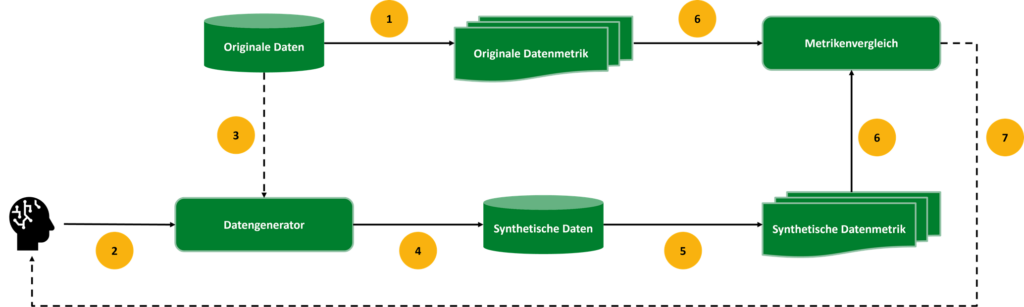
Zunächst werden die Originaldaten analysiert und verschiedene Parameter (z. B. Verteilungsfunktion, Varianz etc.) aus den Daten berechnet [1]. Durch Anwendung dieser Parameter werden Eigenschaften eines Datensatzes vergleichbar und bewertbar [7]. Anschliessend erstellt ein Datengenerator [2] synthetische Daten [4]. Hierfür kommen statistische Methoden, künstliche neuronale Netze oder Agenten-basierte Simulationen[F1] zum Einsatz. Der Datengenerator kann optional mithilfe von Originaldaten kalibriert werden [3]. Im nächsten Schritt werden die Parameter auf den synthetischen Datensatz angewendet [5]. Der Vergleich der synthetischen und originalen Daten nach Anwendung der Parameter erlaubt Rückschlüsse auf die Qualität der künstlichen Daten. Der Generator kann nun angepasst werden und die Qualität der synthetischen Daten optimieren [7].
Use Cases in der Finanzindustrie:
Synthetische Daten eignen sich aufgrund der Verbesserung der Datenbasis von KI-Algorithmen für die Datenverarbeitung und Datenanalyse in der Bank. Zudem erlaubt die Datenanonymität die Verwendung von abstrahierten Daten im gesamten Banken-Ecosystem und ermöglicht intra- und interorganisationale Kollaboration. Der folgende Abschnitt untersucht exemplarische Anwendungsgebiete dieser Technologie im Kontext der Finanzindustrie.
A) Datenaustausch und Kollaboration:
Die DSGVO verhindert den Austausch von persönlichkeitsbezogenen Daten zwischen Banken und sogar teilweise innerhalb einer Bank [12]. Unterschiedliche Abteilungen können somit beim Auswerten der Daten nicht das gesamte Datenpotential der Bank ausschöpfen, Daten müssen durch langwierige Genehmigungsstrukturen an Abteilungen freigegeben werden [13]. Mögliche interne Projekte, für die Abteilungen synthetische Daten benötigen, sind Anti-Money Laundering, Customer Journey Events oder das Risk Management [10], [14]. Synthetische Daten unterstützen Banken zudem beim externen Austausch von Daten zwischen Banken und anderen Institutionen. Dies beinhaltet den Austausch mit Forschungspartnern, potenziellen Geschäftspartnern und offiziellen Institutionen wie dem Staat [15].
B) Anti-Money Laundering:
Geldwäsche (Money Laundering) bezeichnet die Einschleusung von Geld aus illegalen Aktivitäten in das reguläre Finanzsystem. Synthetische Daten können durch die Vervielfältigung von richtig erkannten Betrugsfällen den Prozess der Mustererkennung bei Geldwäscheaktivitäten unterstützen. Potenzielle Accounts, Transaktionen, Zahlungen, Abhebungen oder Käufe können durch grössere Menge von synthetischen Trainingsdaten vom KI-Algorithmus besser identifiziert werden. Aufgrund der Anonymität der Daten können Datensätze verschiedener Banken an Institutionen und Regierungen übermittelt werden und dort von diesen als zusammengeführter Datensatz untersucht werden. Die Muster der kriminellen Aktivitäten sind weiterhin in den synthetischen Daten ersichtlich, ohne den Datenschutz zu gefährden [9]. Dies ermöglicht interorganisatorische Prozesse bei der Bekämpfung von Geldwäsche-Aktivitäten bei gleichzeitiger Einhaltung des Datenschutzes. Besonders bei der Geldwäscheerkennung sind sehr grosse Datensätze von enormer Bedeutung, um statistische false-positive Meldungen zu vermeiden [16].
C) Marktsimulationen und Datenlücken:
Synthetische Daten ermöglichen Banken die Simulation sowie das Testen verschiedener Strategien unter extremen Bedingungen. Hierzu zählen Zusammenbrüche des Marktes oder Systemausfälle auf Seiten der Bank [15]. Lücken in der bestehenden Dokumentation solcher Zwischenfälle können zudem mithilfe von synthetischen Daten geschlossen werden (partiell synthetische Daten). Das Beispiel der Corona-Pandemie aus der Automobilindustrie zeigt: unmittelbar nach dem 1. Lockdown im Jahr 2020 waren viele Unternehmen von den Herausforderungen der Pandemie überfordert. Hersteller mussten die Arbeit einstellen und die Produktion stand vielerorts still [17]. Zur lückenlosen Planung und Steuerung eines Werkes werden dennoch Datensätze für diesen Zeitraum benötigt. Synthetische Daten erlauben die Schliessung dieser Datenlücken durch die Generierung künstlicher Daten.
Fazit
Disruptive Technologien wie KI steigern die Relevanz und den Bedarf an synthetischen Daten kontinuierlich. Finanzinstitute können diese Daten nutzen, um interne und externe Datensätze anzureichern und um diese zu anonymisieren. Dennoch gilt: es ist nicht ausgeschlossen, dass mithilfe von Technologie und Wissen ein synthetischer Datensatz zum Originaldatensatz zurückverfolgt werden kann. Allerdings können durch synthetische Daten branchenweite Erkenntnisse generiert werden, der ROI der KI gesteigert werden und Ecosysteme entstehen [18].
[F1] Agenten-basierte Simulationen ermöglichen die Simulation und Analyse von Wirkungszusammenhängen in komplexen ökonomischen Systemen [11]
Quellen
[1] A. Fernandez, “Artificial Intelligence in Financial Services,” SSRN Journal, 2019, doi: 10.2139/ssrn.3366846. [2] PricewaterhouseCoopers, “Smart Identification & Verification – Managed Service trifft Künstliche Intelligenz. Eine KYC Lösung von PwC.,” PwC. https://www.pwc.de/de/finanzdienstleistungen/smart-identification-and-verification.html (accessed Nov. 18, 2021). [3] S. Magaram, “Improving Anti-Money Laundering Models with Synthetic Data,” GAB | The Global Anticorruption Blog, Jun. 04, 2021. https://globalanticorruptionblog.com/2021/06/04/improving-anti-money-laundering-models-with-synthetic-data/ (accessed Oct. 25, 2021). [4] G. Krasadakis, “Data Quality in the era of A.I.,” The Innovation Machine, Oct. 11, 2020. https://medium.com/innovation-machine/data-quality-in-the-era-of-a-i-d8e398a91bef (accessed Nov. 18, 2021). [5] L. Goasduff, “The 4 Trends That Prevail on the Gartner Hype Cycle for AI, 2021,” www.gartner.com. https://www.gartner.com/en/articles/the-4-trends-that-prevail-on-the-gartner-hype-cycle-for-ai-2021 (accessed Oct. 25, 2021). [6] E. A. Lopez-Rojas and S. Axelsson, “Money Laundering Detection using Synthetic Data,” p. 8. [7] S. Guhr, “Synthetische Daten für die digitale Transformation im Banking,” www.der-bank-blog.de, Feb. 11, 2021. https://www.der-bank-blog.de/synthetische-daten-transformation/marketing/37670443/ (accessed Oct. 28, 2021). [8] V. Lettieri, “Daten-Synthetisierung – eine Alternative zur Anonymisierung?,” datenschutz-notizen | News-Blog der datenschutz nord Gruppe, Sep. 02, 2021. https://www.datenschutz-notizen.de/daten-synthetisierung-eine-alternative-zur-anonymisierung-5130963/ (accessed Oct. 28, 2021). [9] E. Devaux, “What is privacy-preserving synthetic data?,” www.statice.ai, 2020. https://www.statice.ai/post/what-is-synthetic-data-introduction (accessed Oct. 25, 2021). [10] J.P. Morgan AI Research, “Synthetic Data,” www.jpmorgan.com. https://www.jpmorgan.com/technology/artificial-intelligence/initiatives/synthetic-data (accessed Oct. 25, 2021). [11] A. Deckert and R. Klein, “Agentenbasierte Simulation zur Analyse und Lösung betriebswirtschaftlicher Entscheidungsprobleme,” J Betriebswirtsch, vol. 60, no. 2, pp. 89–125, Jun. 2010, doi: 10.1007/s11301-010-0058-6. [12] “Personenbezogene Daten: Regeln und Rechte gemäß DSGVO,” Streitlotse, Jun. 19, 2019. https://www.advocard.de/streitlotse/internet-und-konsum/datenschutz/personenbezogene-daten-regeln-und-rechte-gemaess-dsgvo/ (accessed Nov. 18, 2021). [13] S. Assefa, “Generating Synthetic Data in Finance: Opportunities, Challenges and Pitfalls,” SSRN Journal, 2020, doi: 10.2139/ssrn.3634235. [14] Reciprocity, “Using Artificial Intelligence in Risk Management,” Reciprocity, Sep. 09, 2021. https://reciprocity.com/blog/using-artificial-intelligence-in-risk-management/ (accessed Nov. 18, 2021). [15] C. Dilmegani, “4 Synthetic data applications to enable finance innovation in ’21,” www.research.aimultiple.com, Jun. 24, 2021. https://research.aimultiple.com/synthetic-data-finance/ (accessed Oct. 28, 2021). [16] P. Craig, “How to trust the machine: using AI to combat money laundering,” www.ey.com, Sep. 03, 2019. https://www.ey.com/en_gl/trust/how-to-trust-the-machine–using-ai-to-combat-money-laundering (accessed Oct. 28, 2021). [17] E.-D. Wilfried, “Coronavirus: Welche Werke Autobauer stillgelegt haben, wo sie wieder anlaufen,” Apr. 01, 2020. https://www.manager-magazin.de/unternehmen/autoindustrie/coronavirus-welche-werke-autobauer-stillgelegt-haben-wo-sie-wieder-anlaufen-a-1305675.html (accessed Nov. 18, 2021). [18] S. Weyer, “Synthetische Daten: Datenschutz und Datennutzung in Zeiten von DSGVO,” Jul. 17, 2019. https://www.computerwoche.de/a/datenschutz-und-datennutzung-in-zeiten-von-dsgvo,3547346 (accessed Nov. 18, 2021).

Leipzig in Wirtschaftsinformatik mit dem Forschungsschwerpunkt disruptive Technologien. Seitdem untersucht er den Einfluss
von künstlicher Intelligenz und Blockchain auf Unternehmen in verschiedenen Industrien. Derzeit studiert Lasse im Master Wirtschafsinformatik.