
“Data-centric AI” – A shift in the AI mindset?
Digitalization enables the permanent collection and processing of various data about a company. The amount of this data has continued to increase in recent years. Statista predicts a fivefold increase in the amount of data worldwide by 2025 compared to 2018 [1]. Emerging technologies and trends such as Big Data have led to the emergence of new services and underlying business models. In this context, more and more companies are focusing on introducing and offering data-driven services: Data is penetrating further and further into the core business of the company [2, 3].
However, data alone does not yet contribute to value creation. Only when data is enriched with relevance and purpose – e.g., through analysis and processing – does it become information which can then generate added value further down the line. To evaluate business-relevant information, companies are increasingly relying on new technologies like artificial intelligence (AI) [4].
What Does the Buzzword “Artificial Intelligence” Entail?
It should be said at the outset that science has not yet been able to agree on a uniform definition of artificial intelligence. Just as with human intelligence, many factors play a role: Human intelligence, for example, encompasses areas such as logical-mathematical intelligence but also verbal-linguistic intelligence. In artificial intelligence, the range of methods is similarly broad, from simple calculations (data analytics) to image, text and speech recognition [5]. In general, the buzzword AI is understood to mean intelligent programs that are able to handle complex tasks autonomously [6].
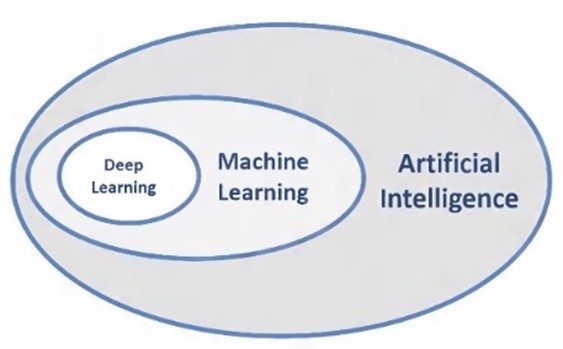
To further explain artificial intelligence, the distinction is made between it and terms such as machine learning and deep learning, which are often used synonymously. As can be seen in Figure 1, deep learning is a subfield of machine learning, which in turn is a subfield of artificial intelligence – so whoever says AI is usually right. Anyone who wants to be perceived as an expert in the field can specify AI even further by using the term machine learning or deep learning. This could probably be continued ad infinitum, as AI is currently being researched particularly diligently – but more on that later.
Machine learning methods take different forms and are used for autonomous extraction of insights from data. Thus, no explicit programming is required to solve a problem [8]. The methods follow defined logics such as a statistical regression or a decision tree algorithm [9]. Furthermore, artificial neural networks can be used for machine learning. These networks imitate the functioning of the human brain and consist of different layers and nodes [10]. Information and data (input) are evaluated at the nodes and transferred to the next layer. Afterwards, the network delivers a result (output), just like an algorithm.
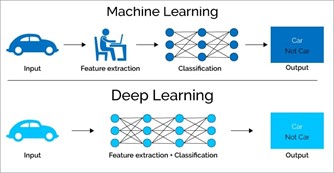
In machine learning, a distinction is made between supervised machine learning and unsupervised machine learning. In supervised machine learning, humans must manually intervene in the training process and provide the algorithm with the results of the pattern recognition and, if necessary, important features of the data (figure 2: Feature Extraction). Only in this way is the algorithm able to recognize a relationship between the input data and the output based on these specifications. The example of automobile images illustrates the situation. Only if a human specifies which images are actually cars can the algorithm classify cars as cars on unknown images (figure 2: Classification). Supervised learning is often equated with the traditional machine learning approach. In this context, the term “model” is used. A machine learning model is a file that contains the described relationships and patterns and can be reused [11].
Unsupervised learning eliminates the need for human manual intervention and enables the algorithm to recognize inputs and patterns on its own [6]. Cluster methods or artificial neural networks are used here. Especially the latter allow for autonomous analysis, as data is strongly connected between the layers of the network, making learning effects possible. Complex (multi-layered) artificial neural networks are called deep learning. [6].
These remarks demonstrate the close interconnection between the different AI concepts. Trained models and insights can subsequently be used in programs that require a high degree of “intelligence” [6]. An example of an AI-based program is an intelligent chatbot that uses natural language processing (NLP) to enable human-like interaction [12].
Traditional Use of AI and Limitations
The traditional approach of AI focuses on the model training process [13]. By iteratively improving mathematical models, the quality of the results increases over time (“model-centric AI”). While the training of the model receives great attention, the underlying data often takes a back seat. This approach works particularly well with Internet corporations, as they have vast amounts of data and the capabilities to analyze it. In contrast, there is hardly any potential for the use of AI in small companies with this approach due to a lack of data volumes [14]. Therefore, it is worth taking a look at the data.
Handling data is very similar to cooking. While the preparation of the ingredients takes a relatively long time, the actual process of cooking is often very short. Scientist Andrew Ng takes this approach and applies it to AI [15]. The result of this is an approach to AI that seems counterintuitive at first glance. It focuses on the data and deals with the optimal preparation and use of the data for model training (“data-centric AI”).
What Exactly Is Data-Centric AI?
The concept of “data-centric AI” is described as “transitioning from model focus to the underlying data set used for training and evaluation of the AI model” [16].
But what constitutes data and what properties must be considered in “data-centric AI”? Data sets have various properties that can be described with the help of the concept of the “seven Vs of Big Data” [17] (Figure 3). The property “volume” describes the size of the data set, “velocity” the speed with which it is generated and processed. “Variety” encompasses the variety of different data types (audio, video, text) that the data set contains, while “veracity” stands for the quality and consistency of the data. Consistent data is correct and free of contradictions. When a data field is replicated (for example, in another database), all replications must have the same data types and content [18]. “Validity” examines the meaningfulness of the data in relation to the underlying problem. “Volatility” refers to the rate of change of the data over its life cycle and can become a problem in some circumstances – for example, if the data is social media comments that can be revised and/or deleted and that other users can interact with. Only with the help of a data strategy and by using data in the right way can companies generate value from it. “Value” again underscores Andrew Ng’s approach.
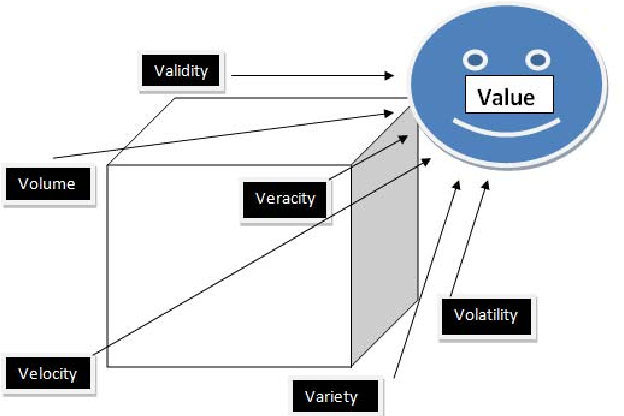
While Big Data involves all 7 Vs, “data-centric AI” focuses on the quantity (volume) and the consistency and quality of data (veracity). By continuously improving these attributes and thus the data input, the value of the resulting information should be increased [19]. The focus thus shifts from the quantity of data to the quality. While “model-centric AI” optimizes the model and feeds it with more and more new data, “data-centric AI” considers the model code as unchangeable and optimizes the given amount of data.
Framework for Implementing a Data-Centric Machine Learning Project
The improved data will be used primarily in machine learning operations (MLOps), where it will replace the multitude of individual methods for cleaning and preparing data [14]. MLOps describes the integration and use of ML models in the enterprise in the form of software. Here, the focus is on the development, deployment and monitoring of machine learning models [20]. Systematic processes allow ML-based applications to be integrated efficiently and continuously in companies. Standardized processes also allow cross-company integration.
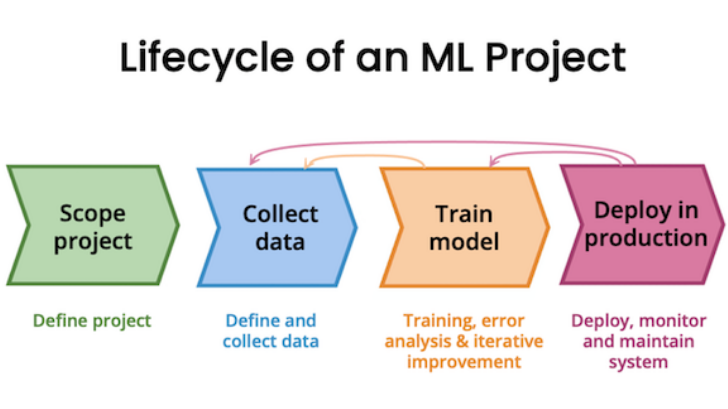
The presented data-centric framework is based on the steps of the life cycle of an ML project (Fig. 4) and extends it by the following steps, which are represented by the arrows in the figure: After successfully training the model, an error analysis is performed to identify the data that cause problems for the model (e.g., formatting errors when merging datasets). Subsequently, missing entries can be corrected or the existing data sets can be adjusted. Test data sets allow the simulation of the model in a real environment. This allows conclusions to be drawn about the data quality and the underlying data to be further improved. [14].
Advantages
The data focus in machine learning, unlike the traditional approach, can be implemented in all industries and does not depend on large amounts of data. A study by “LandingAi” shows directly measurable improvements in AI projects upon implementing the new approach. In particular, the training of the model (10 times faster) as well as the time from the start of development to the productive use of a model have been enormously reduced (up to 65%) by using the data-centric approach. In addition, models are reported to be up to 40% more accurate. The joint development of standards (MLOps Framework) increases collaboration between quality managers, experts and developers and thus enables more efficient execution of AI projects [19]. In addition to improved data quality and reduced redundancy, companies benefit from “data-centric AI” through lower costs and clear data structures. By improving the quality of input data for AI programs, confidence in the information derived from it and the decisions made on the basis of this information increases. [22].
Challenges
The data used must always be kept up to date in order to benefit from the added values of this concept. Therefore, the monitoring of the data as well as its adaptation are relevant challenges in this subject area [23, 24]. Data adjustments concern, for example, the structure of the data (lists, fields), data types (letters, numbers) or units of measurement (liters, euros). Through monitoring, changes in data records can be easily tracked. This step is particularly relevant because the performance of the AI model is now mainly dependent on the underlying data. Domain experts play an important role in “data-centric AI.” Additional contextual knowledge in their respective areas of expertise allows them to more precisely formulate data requirements and verify compliance, thus strongly influencing the quality of the results [22].
Possible Application Areas in the Financial Industry
Big Data is currently being used in various areas of the financial industry for the application of AI technologies. These include, for example, algo trading, asset management, and credit scoring [25]. The introduction of uniform data standards as well as the improvement of data quality also provide improved results of AI technologies in these areas. Furthermore, “data-centric AI” opens up new possibilities for the use of AI in the financial industry. For example, even smaller data sets can already be used for analysis by AI technologies. Concrete use cases do not yet exist in the financial industry, as data-centric AI is a very recent phenomenon and banks are certainly not among the “early adopters” due to their low risk appetite.
Nevertheless, it is of enormous importance for banks to be aware of this trend and, in general, to focus much more on data quality in the case of small data volumes. Economic shocks occur again and again in the financial industry, as well as in other industries, which, thanks to globalization, affect all companies worldwide in the short term. Companies can no longer fall back on their vast amounts of historical data, which were created in a different context and are therefore not suitable for forecasting the future. Such a shock also occurred at the beginning of the Corona pandemic: At the beginning of the pandemic, customers’ payment patterns suddenly changed, which likely made fraud detection much more difficult. Furthermore, short-term loans were suddenly requested by mainly smaller companies in order to be able to survive the coming lockdown – with what default risk do we assess these cases? How is the interest rate to be paid calculated in an exceptional situation? This is exactly the kind of case where data-centric AI can assist: Instead of focusing on Big Data, the focus is now on the quality of the data. This should be guaranteed throughout the entire ML life cycle and embedded in MLOps activities with the help of systematic and efficient processes. This gives companies that do not have Big Data for various reasons an opportunity to use AI technologies successfully. But even experienced companies benefit from an increase in data quality through the measurable improvement of their AI-supported analyses.
Related links
[1] Tenzer, F., “Data – Volume of Data Generated Worldwide 2025,” Statista, 2020. https://de.statista.com/statistik/daten/studie/267974/umfrage/prognose-zum-weltweit-generierten-datenvolumen/ [2] Dr. Hoßbach, N., “Data-Driven Business Models,” Fraunhofer IIS Supply Chain Services Working Group. https://www.scs.fraunhofer.de/de/forschungsfelder/datengetriebene-geschaeftsmodelle.html [3] Dr. Rieger, V., and D. Dr. Drube, “Service- and data-centric business models based on IoT and Industrie 4.0,” 2019. https://detecon.com/de/journal/service-und-datenzentrierte-geschaeftsmodelle-auf-basis-von-iot-und-industrie-40 [4] Kiron, D., and M. Schrage, “Strategy For and With AI,” MIT Sloan Management Review, 2019. [5] Dietzmann, C., and R. Alt, “Assessing the Business Impact of Artificial Intelligence,” (2020). [6] Tiedemann, M., “AI, artificial neural networks, machine learning, deep learning: We shed light on the terms surrounding artificial intelligence”, Alexander Thamm GmbH, 2018. https://www.alexanderthamm.com/de/blog/ki_artificial-intelligence-ai-kuenstliche-neuronale-netze-machine-learning-deep-learning/ [7] Holzinger, A., P. Kieseberg, E. Weippl, and A.M. Tjoa, “Current Advances, Trends and Challenges of Machine Learning and Knowledge Extraction: From Machine Learning to Explainable AI,” Machine Learning and Knowledge Extraction, Springer International Publishing (2018), 1-8. [8] Wolfewicz, A., “Deep learning vs. machine learning – What’s the difference?”, Levity, 2021. https://levity.ai/blog/difference-machine-learning-deep-learning [9] Wuttke, L., “Machine Learning vs. Deep Learning: Where is the difference?”, datasolut GmbH, 2021. https://datasolut.com/machine-learning-vs-deep-learning/ [10] Garbade, D.M.J., “Clearing the Confusion: AI vs Machine Learning vs Deep Learning Differences,” Medium, 2021. https://towardsdatascience.com/clearing-the-confusion-ai-vs-machine-learning-vs-deep-learning-differences-fce69b21d5eb [11] QuinnRadich, “What is a Machine Learning Model?”, https://docs.microsoft.com/de-de/windows/ai/windows-ml/what-is-a-machine-learning-model [12] Weber, R., “Chatbot types: click chatbot vs. NLP chatbot,” moin.ai, 2021. https://www.moin.ai/blog/natuerliches-sprachverstandnis-nlp-vs-gefuehrte-chat-dialoge [13] Radečić, D., “Data-centric vs. model-centric AI? The Answer is Clear,” Medium, 2021. https://towardsdatascience.com/data-centric-vs-model-centric-ai-the-answer-is-clear-4b607c58af67 [14] Press, G., “Andrew Ng Launches A Campaign For Data-Centric AI,” Forbes. https://www.forbes.com/sites/gilpress/2021/06/16/andrew-ng-launches-a-campaign-for-data-centric-ai/ [15] DeepLearningAI, A Chat with Andrew on MLOps: From Model-centric to Data-centric AI, 2021. [16] “NeurIPS Data-Centric AI Workshop”, 2021. https://datacentricai.org/ [17] Khan, M.A., M.F. Uddin, and N. Gupta, “Seven V’s of Big Data understanding Big Data to extract value”, Proceedings of the 2014 Zone 1 Conference of the American Society for Engineering Education, (2014), 1–5. [18] “Datenkonsistenz”, https://www.gif-ev.de/glossar/view_contact/458 [19] Landing AI, “Data-Centric AI”, Landing AI, 2022. https://landing.ai/data-centric-ai/ [20] Wuttke, L., “Was ist ML-Ops? (Machine Learning Operations)”, datasolut GmbH. https://datasolut.com/wiki/was-ist-mlops/ [21] Muaz, U., “From Model-centric to Data-centric Artificial Intelligence”, Medium, 2021. https://towardsdatascience.com/from-model-centric-to-data-centric-artificial-intelligence-77e423f3f593 [22] Patel, H., “Data-Centric Approach vs Model-Centric Approach in Machine Learning”, neptune.ai, 2021. https://neptune.ai/blog/data-centric-vs-model-centric-machine-learning [23] Clemente, F., “From model-centric to data-centric”, Medium, 2021. https://towardsdatascience.com/from-model-centric-to-data-centric-4beb8ef50475 [24] Polyzotis, N., and M. Zaharia, “What can Data-Centric AI Learn from Data and ML Engineering?”, arXiv:2112.06439 [cs], 2021. [25] OECD, ed., Sustainable and resilient finance, OECD, Paris, 2020.
{kind=link}


- Data Lineage: A Path to the Data-Driven Enterprise? - 26.08.2022
- Synthetic Data – The Future of Data-Driven Financial Services? - 23.12.2021
- Gaia-X – A Revolution for the Financial Industry? - 12.11.2021