Federated Learning – Efficient Machine Learning That Respects Privacy?
In 2021, fines of 1.3 billion euros were imposed in Europe on companies that violated data protection and the current General Data Protection Regulation (GDPR) [1]. This amount has increased sevenfold in the space of one year, compared with 172 million euros in 2020. Companies in Switzerland also face high penalties [2]. Interestingly, the highest individual fines in Europe were imposed on Big Techs such as Amazon and companies of the Meta Group.
But at second glance, this finding is little surprising; after all, Big Techs use huge amounts of data and evaluate it with machine learning and other artificial intelligence methods [3]. Data is one of their most important resources and determines their dominance in the market. In addition to analysis, the monetization of data is also an important pillar of the business models of Big Techs. In addition, data is used for developing new services and improving marketing [4].
While the customers of the past tolerated the use and exploitation of their own data, in early 2021 the Meta Group found that this attitude had changed: In January 2021, many users left the messenger service WhatsApp due to a change in its privacy policy and switched to alternative providers such as Signal [5]. The customers of the future are critically evaluating existing business models, and data protection is becoming increasingly important to them [6]. This movement does not stop at the Big Techs and will lead to a change in the way the topic of “data protection” is handled. In the EU, this trend is additionally accelerated by the regulator and the European Union’s General Data Protection Regulation (GDPR). Citizens are to regain control over their own data and be able to decide how it is used [7].
In addition to Big Techs, banks are also affected by these changes. Especially in the financial industry, customers expect high standards regarding data protection and the integrity of their own data. From a regulatory perspective, breaches of the guidelines also have high financial consequences [8]. Nevertheless, from a value creation perspective, it is essential for banks to analyze customer data using statistical methods and algorithms. The banks are thus caught between the need to protect data privacy and the enforcement of their own business model.
To address this problem, the concept of “federated learning” has become established in the market in recent years [9]. This concept can be assigned to the field of artificial intelligence and machine learning. In our article on the topic “Data-centric AI – A change in the AI mindset?” we have already explained the basics of machine learning and positioned the buzzword within the field of artificial intelligence. The article enables the understanding of important basics and concepts of artificial intelligence as well as machine learning.
Today’s blog post explores the federated learning approach and how decentralization and local data storage can help Big Techs and banks maintain data protection and privacy.
What Is Federated Learning Exactly?
Basically, federated learning, also known as “collaborative learning” or “decentralized learning”, is a machine learning technique [9] that involves multiple devices collaborating in a decentralized manner to solve a business problem together. This principle can be considered as a kind of “sharing economy”[i] in the data environment. Federated learning was discovered at the intersection of on-device AI, blockchain, edge computing, and the IoT [11]. At first glance, these are a lot of different terms; the following section classifies some of these terms and shows different manifestations of machine learning.
Let’s start with the question of what machine learning is and what makes it so special. Machine learning enables the autonomous extraction of information from data using algorithms and statistical models [12]. Information about patterns in data is stored in a model and improved over time. This process is called model training [13] (for more information and classification in the subject area of artificial intelligence, see blog post: “Data-centric AI – A change in the AI mindset?”.
From a technical point of view, different approaches exist for training a machine learning model. In this context, a distinction is made between three basic concepts (see figure 1). While in classical (centralized) machine learning (1) the models and data are trained and stored on central servers, this approach is modified in distributed machine learning (2) and federated learning (3) [14].

Distributed machine learning is especially popular in the big data environment. While data is stored centrally, distributed machine learning allows the use of multiple resources (ex: multiple servers) for model training [15]. Thus, more computing power can be provided, which increases the performance of the training and the models. Particularly in the context of big data distributed machine learning is suitable for the processing of data [16] [17]. The larger data sets offer new possibilities for model training, models can be trained with versatile data sets and parameters. This increases the quality of the models and allows companies to offer improved services and products to their customers. [18].
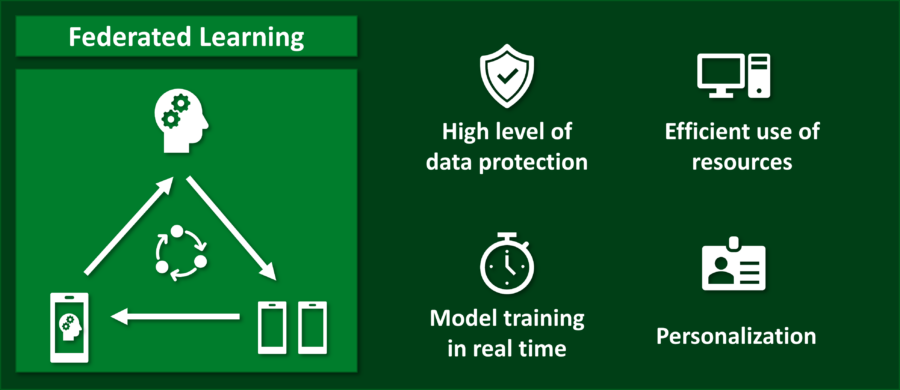
Federated learning differs from the other two approaches in that the data used is always stored decentrally and the models are trained decentrally. Only the anonymized, trained ML models are processed and aggregated on central servers [19]. Figure 2 briefly illustrates this process.

First, a machine learning model is sent from a central server to a decentralized computing unit (ex: cell phone). The decentralized computing unit now trains the model with its own local data. The improved model is then sent back to the server. During the entire transmission, the encryption of the data is of great importance – companies such as Nvidia already offer different approaches to encryption for this purpose [20]. However, the actual data on which the model is based never leaves the decentralized computing unit. Users therefore always retain control over their data. Several computing units (e.g., several cell phones) can work on model improvement in parallel. All enhancements are then consolidated centrally (Figure 2 – Model aggregation) and enable the use of a centrally optimized model. [19]. The new central model is now sent back to the individual decentralized computing units. This process is repeated iteratively until the model training is completed [21].
Advantages and Challenges
Since the data used never leaves the decentralized computing unit, this approach to machine learning guarantees high data protection standards. The origin of the data always remains secret and no conclusions can be drawn about personal data [21]. In addition, the risk of data loss is minimized by using different data sources and the risk of a single point of failure is reduced [22]. Changes in data sets can be analyzed in real time directly on the devices and incorporated into the central machine learning model, without the need to store data centrally first [23]. Another advantage is the efficient use of hardware resources. No complex and high-performance central servers are required. They only need to be able to consolidate the different ML models [24].
Nevertheless, federated learning is associated with a variety of challenges. From a technical point of view, the availability of the decentralized computing units plays a particularly important role. This includes high bandwidth and performance requirements for the devices. ML models must always be sent encrypted from or to the central servers. Since each device has an individual data set, there may be problems regarding the universal validity and applicability of the ML models. Algorithms are sometimes optimized for data sets with certain properties, e.g., text data, images, or certain file formats. Since the data sets in federated learning are heterogeneous, this can become a major challenge [24]. Scientists are currently working on a federated learning solution in which not only data storage and model training are performed in a decentralized manner, but also the consolidation of ML models. Different approaches exist for this, in which the trained models are consolidated and stored on the blockchain. This would finally do away with the central server in model aggregation [25, 26].

Use Cases
The following two use cases demonstrate the relevance of federated learning in practice.
The first use case comes from the automotive industry. In this case, cars represent a decentralized computing unit. Due to the modern software and hardware in a car, it can be used for providing, storing, and processing data [22]. Sensors enable the collection of data in real time. Furthermore, complex graphics cards and computer systems enable data to be analyzed and used with the help of machine learning methods. Especially in the development and improvement of self-driving cars, the principle of federated learning comes into play. The cars are able to independently create machine learning models of traffic, pedestrians or accidents and thus, for example, maintain the necessary minimum distance at certain speeds or wait when turning until all pedestrians have crossed the road. In addition to collecting data, the car is thus able to make decisions on its own [27]. Federated machine learning not only has the advantage of using information in a privacy-compliant manner, but also the advantage of processing data in real time: in a critical traffic situation, data can be processed directly by the car and there are no latencies due to transmission to and processing on central servers. In extreme cases, this can save lives, e.g. if a pedestrian absent-mindedly runs in front of a car. Finally, the trained models of the individual cars are consolidated at the manufacturer and used for the improvement and development of the cars. Since the trained models and not the data are sent, the principle of data protection is maintained [28, 29].
The second use case originates in the financial industry. For years, there has been a trend toward business ecosystems, and the financial industry is no exception [30]. In an ecosystem, the focus is on sharing data. One initiative that actively drives data sharing is the OpenBankingProject.ch. Fundamental principles of open banking are the use of standardized interfaces (APIs) for sharing data as well as their common use [31]. Sharing data leads to new services and has several advantages for the participants of such an ecosystem. For example, fraud detection processes, credit allocation or personalized services can be offered based on the consolidated data. However, this is precisely where one of the biggest challenges of open banking lies: it is enormously important that customer data (personal data) is handled and analyzed in a trustworthy manner. It is therefore not possible to simply send and evaluate this data between banks. The use of federated learning allows machine learning methods to be applied to customer data while maintaining privacy. The bank takes on the role of a decentralized computing unit and evaluates its own local data. Only the generated ML models subsequently leave the bank after model training and are made available to open banking participants on a central marketplace. In this way, the participants in the open banking ecosystem obtain common insights from the data and can incorporate them into their own value creation.
Implications and Conclusion
In the wake of the “data economy,” the relevance of data and its analysis continues to increase [32]. Especially in the financial industry, customer data integrity and privacy are important pillars of the bank’s business model. Collaboration and data sharing are also on the rise (see OpenBankingProject.ch). Therefore, banks need to look at alternative technologies that enable data mining while maintaining privacy.
Federated learning is a promising method for training machine learning models. The decentralized nature of the computing capacities and the local storage of data at the user make the approach particularly attractive. Customers enjoy high data protection standards, while companies are still able to generate insights from dynamic data using ML models. In practice, many challenges exist (bandwidth, individualized data sets, not a completely decentralized solution) that companies need to consider when implementing federated learning. However, especially when collaborating with other companies, this approach will play an important role in the coming years.
In order to implement and use modern technologies such as federated learning or blockchain, further changes are necessary in various areas of the company. For example, employees must build up knowledge of distributed technologies and the processes in the company must be adapted to the new technological possibilities [33]. This requires a corporate culture that is open to change and is also supported by the company’s strategy and management. Companies can use the business engineering approach to systematize the changes of modern technologies on the levels of strategy, business processes and information systems.
[i] In a sharing economy, assets or services are shared between individuals for free or for a fee, usually over the Internet [10].
Sources
[1] Brandt, M., “Infografik: DSGVO-Bußgelder knacken 2021 die Milliardengrenze”, Statista Infografiken, 2022. https://de.statista.com/infografik/26629/strafen-auf-grund-von-verstoessen-gegen-die-datenschutz-grundverordnung/ [2] Good, P.-L., “Sanktionen & Schadenersatz: Datenschutzgesetz für Unternehmen”, Good Rechtsanwälte, 2021. https://good-zuerich.ch/sanktionen-schadenersatz-revidierten-datenschutzgesetz/ [3] Rosenbush, S., “Big Tech Is Spending Billions on AI Research. Investors Should Keep an Eye Out”, Wall Street Journal, 2022. https://www.wsj.com/articles/big-tech-is-spending-billions-on-ai-research-investors-should-keep-an-eye-out-11646740800 [4] Grothues, L., “Der Rohstoff des 21. Jahrhunderts – Worin liegt der Wert unserer Daten?”, Dr. Datenschutz, 2019. https://www.dr-datenschutz.de/der-rohstoff-des-21-jahrhunderts-worin-liegt-der-wert-unserer-daten/ [5] Hern, A., “WhatsApp loses millions of users after terms update”, The Guardian, 2021. https://www.theguardian.com/technology/2021/jan/24/whatsapp-loses-millions-of-users-after-terms-update [6] Tamo-Larrieux, A., Z. Zihlmann, K. Garcia, and S. Mayer, “The Right to Customization: Conceptualizing the Right to Repair for Informational Privacy”, In 2021. [7] “Was ist die GDPR?”, SailPoint. https://www.sailpoint.com/de/identity-library/was-ist-die-gdpr/ [8] Finanzmagazin, I.T., “Praxistipps: Die Auswirkungen der EU Datenschutz-Grundverordnung (DS-GVO) auf Finanzdienstleister”, IT Finanzmagazin, 2017. https://www.it-finanzmagazin.de/praxistipps-die-auswirkungen-der-eu-datenschutz-grundverordnung-auf-finanzdienstleister-49907/ [9] Bonawitz, K., P. Kairouz, B. McMahan, and D. Ramage, “Federated Learning and Privacy: Building privacy-preserving systems for machine learning and data science on decentralized data”, Queue 19(5), 2021, pp. Pages 40:87-Pages 40:114. [10] “Oxford Learner`s Dictionaries – sharing economy”, Oxford Learner`s Dictionaries. https://www.oxfordlearnersdictionaries.com/definition/english/sharing-economy [11] Bag, S., “Federated Learning for Beginners | What is Federated Learning”, Analytics Vidhya, 2021. https://www.analyticsvidhya.com/blog/2021/05/federated-learning-a-beginners-guide/ [12] Wolfewicz, A., “Deep learning vs. machine learning – What’s the difference?”, Levity, 2021. https://levity.ai/blog/difference-machine-learning-deep-learning [13] Brownlee, J., “Difference Between Algorithm and Model in Machine Learning”, Machine Learning Mastery, 2020. https://machinelearningmastery.com/difference-between-algorithm-and-model-in-machine-learning/ [14] McMahan, B., and D. Ramage, “Federated Learning: Collaborative Machine Learning without Centralized Training Data”, Google AI Blog. http://ai.googleblog.com/2017/04/federated-learning-collaborative.html [15] Srinivasan, A., “Difference between distributed learning versus federated learning algorithms”, KDnuggets. https://www.kdnuggets.com/difference-between-distributed-learning-versus-federated-learning-algorithms.html/ [16] Khan, M.A., M.F. Uddin, and N. Gupta, “Seven V’s of Big Data understanding Big Data to extract value”, Proceedings of the 2014 Zone 1 Conference of the American Society for Engineering Education, (2014), 1–5. [17] Verbraeken, J., M. Wolting, J. Katzy, J. Kloppenburg, T. Verbelen, and J.S. Rellermeyer, “A Survey on Distributed Machine Learning”, ACM Computing Surveys 53(2), 2020, pp. 30:1-30:33. [18] Mani, C., “Council Post: How Is Big Data Analytics Using Machine Learning?”, Forbes, 2020. https://www.forbes.com/sites/forbestechcouncil/2020/10/20/how-is-big-data-analytics-using-machine-learning/ [19] Chandorikar, K., “Introduction to Federated Learning and Privacy Preservation”, Medium, 2020. https://towardsdatascience.com/introduction-to-federated-learning-and-privacy-preservation-75644686b559 [20] Roth, H., M. Zephyr, and A. Harouni, “Federated Learning with Homomorphic Encryption”, NVIDIA Technical Blog, 2021. https://developer.nvidia.com/blog/federated-learning-with-homomorphic-encryption/ [21] Bracht, O., Whitepaper – Federated Learnin, Mit Federated Learning zu erfolgreichen KI- und Data-Science-Projekten, [22] Kozlowski, A., and M. Wisniewski, “Federated Learning in the Automotive Industry”, Grape Up, 2021. https://grapeup.com/blog/machine-learning-at-the-edge-federated-learning-in-the-automotive-industry/ [23] Zhang, H., J. Bosch, and H.H. Olsson, “Real-time End-to-End Federated Learning: An Automotive Case Study”, arXiv:2103.11879 [cs], 2021. [24] Dilmegani, C., “What is Federated Learning (FL)? Techniques & Benefits in 2022”, 2021. https://research.aimultiple.com/federated-learning/ [25] Li, D., D. Han, T.-H. Weng, et al., “Blockchain for federated learning toward secure distributed machine learning systems: a systemic survey”, Soft Computing, 2021. [26] Kim, H., J. Park, M. Bennis, and S.-L. Kim, “Blockchained On-Device Federated Learning”, arXiv:1808.03949 [cs, math], 2019. [27] Ravindra, S., “The Machine Learning Algorithms Used in Self-Driving Cars”, KDnuggets, 2017. https://www.kdnuggets.com/the-machine-learning-algorithms-used-in-self-driving-cars.html/ [28] Shenwai, T., “Introduction To Federated Learning: Enabling The Scaling Of Machine Learning Across Decentralized Data Whilst Preserving Data Privacy”, MarkTechPost, 2022. https://www.marktechpost.com/2022/01/25/introduction-to-federated-learning-enabling-the-scaling-of-machine-learning-across-decentralized-data-whilst-preserving-data-privacy/ [29] Du, Z., C. Wu, T. Yoshinaga, K.-L.A. Yau, Y. Ji, and J. Li, “Federated Learning for Vehicular Internet of Things: Recent Advances and Open Issues”, IEEE Open Journal of the Computer Society 1, 2020, pp. 45–61. [30] Riasanow, T., R. Floetgen, D. Soto Setzke, M. Böhm, and H. Krcmar, The Generic Ecosystem and Innovation Patterns of the Digital Transformation in the Financial Industry, 2018. [31] Long, G., Y. Tan, J. Jiang, and C. Zhang, “Federated Learning for Open Banking”, springerprofessional.de, 2020. https://www.springerprofessional.de/federated-learning-for-open-banking/18626416 [32] www.aberratio.de, aberratio G., Hamburg, “Data Economy: Bundesverband Digitale Wirtschaft (BVDW) e.V.”, https://www.bvdw.org/themen/data-economy/ [33] Heines, R., N. Kannengießer, B. Sturm, R. Jung, and A. Sunyaev, “Need for Change: Business Functions Affected by the Use of Decentralized Information Systems”, ICIS 2021 Proceedings, 2021.

- Data Lineage: A Path to the Data-Driven Enterprise? - 26.08.2022
- Synthetic Data – The Future of Data-Driven Financial Services? - 23.12.2021
- Gaia-X – A Revolution for the Financial Industry? - 12.11.2021

In addition to her work at the bank, Dr. Wulfmeyer appears as a speaker, advocates for executive education in data literacy, and coaches young executives.
Dr. Wulfmeyer holds a PhD in Financial Modeling from the University of St. Gallen (HSG, Switzerland) and a Diploma in Economics from the University of Mannheim (Germany).